將網頁轉換成PDF的方法很多種
比較常見且最簡單的方式就是直接使用列印功能
之前是從全國書目網搜尋書籍ISBN
但是這個網站好像蠻容易掛掉、沒反應
所以嘗試從其他網站查詢資訊
也試試看不同網站架構、資料型態的處理
得到的回傳書籍資料是JSON格式,可以用 JSON.parse( )解析內容
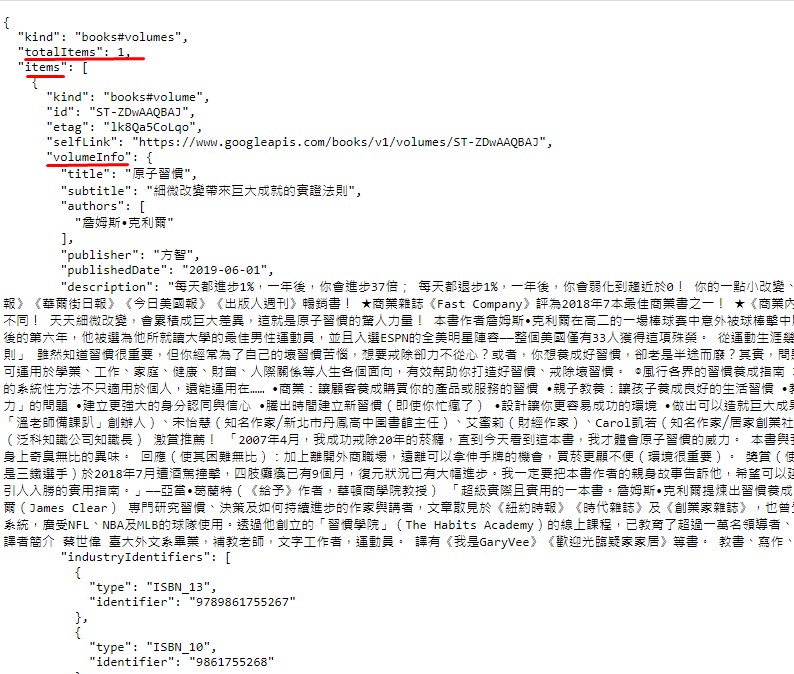
totalItems → 如果有資料的話為1,可以用來判斷是否要進行後面的資料寫出
items→資料型態是 key : value ,因為也只有1筆,所以可以用 items[0]來取出所有資料
-volumeInfo→書籍資料都在這個屬性之下,資料型態也是 key : value ,在用屬性名稱取出對應的值
如果直接用瀏覽器連結的話就不需要,應該是自動偵測瀏覽器語言
原本後面還有加Google Book API 的金鑰,但是不加這個也是可以抓到資料
會得到網頁的搜尋結果,所以必須解析網頁內容
由於WorldCat是跨資料庫的搜尋,搜尋結果會列出資料庫裡符合的資料
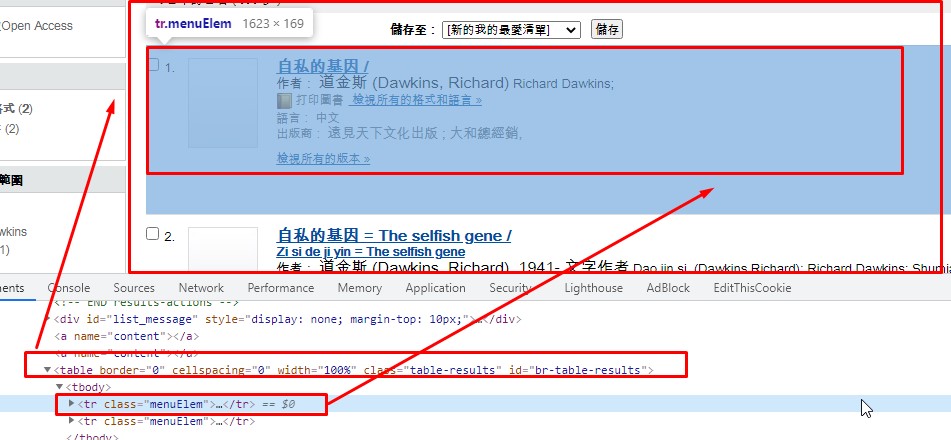
從中取出需要的表格-#br-table-results
再依據HTML內容分割所需要的欄位資料
沒有加這個參數,除了書籍資料之外的資料都會是英文,例如:作者,會變成 author

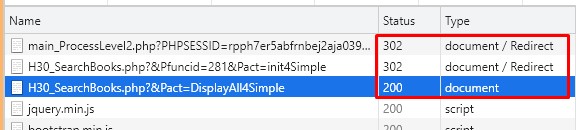
Status 302 表示會有重新導向
目前的處理方式
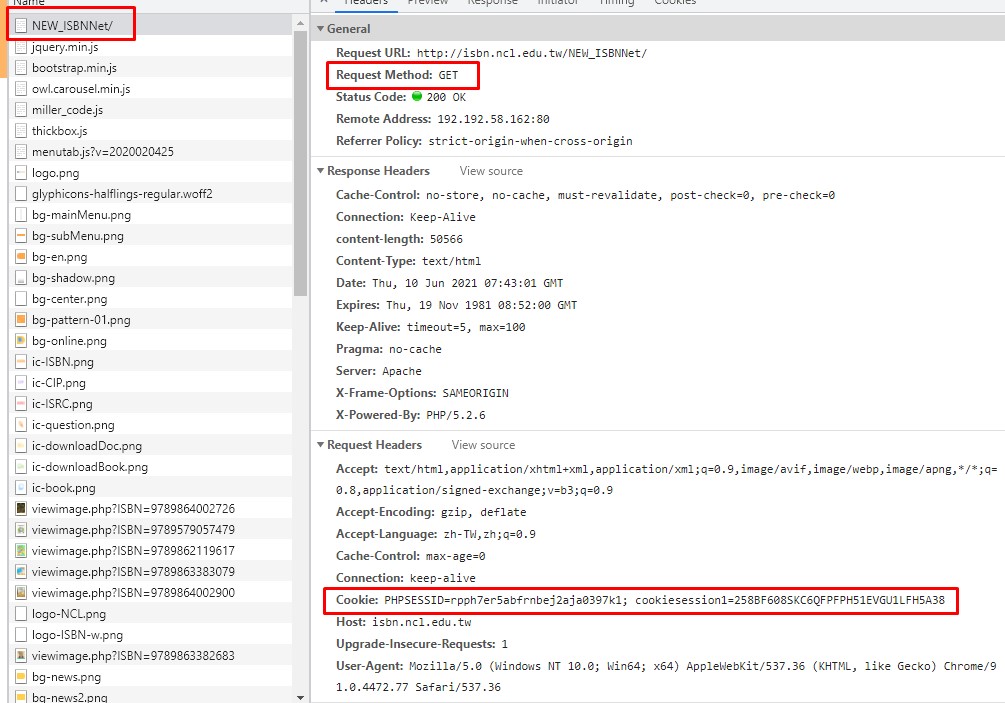
抓取Cookie →PHPSESSID的值
原因在於網站在開啟之後就會自動生成 Cookie PHPSESSID
並且寫入HTML,例如:導覽列的分頁網址
可能網站後端有機制在驗證
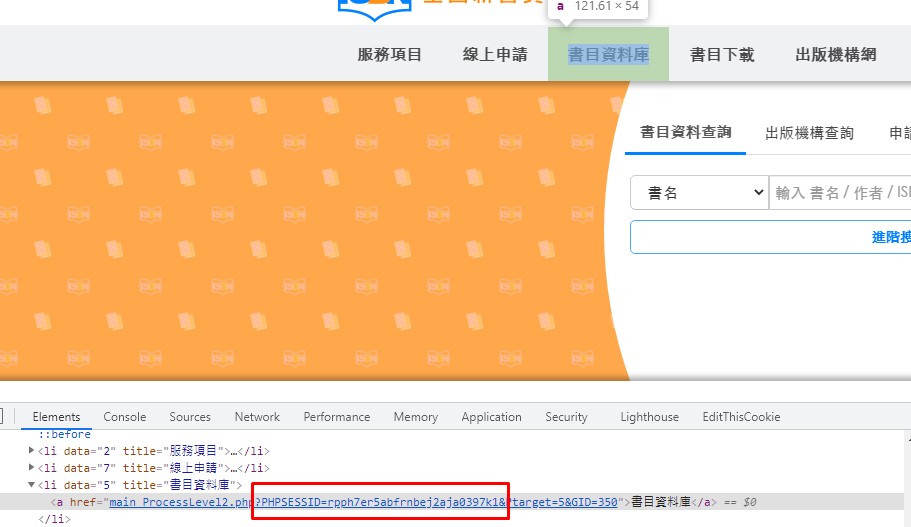
所以先用外部資料庫Cheerio解析HTML,取得導覽列的網址,再拆解字串取得Cookie
設定成 headers裡的Cookie的值
但是有時候會沒有這個值,只會回傳cookiesession1
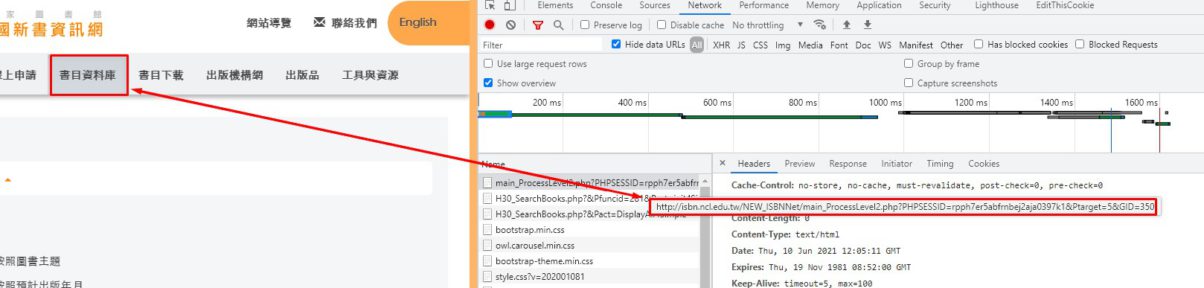
要注意的部分:雖然看起來點擊”書目資料庫”會在連結中帶入PHPSESSID
但是fetch( )時,必須將 PHPSESSID設定在headers,而不是網址字串
網址也會被轉向到 Location: H30_SearchBooks.php?&Pfuncid=281&Pact=init4Simple
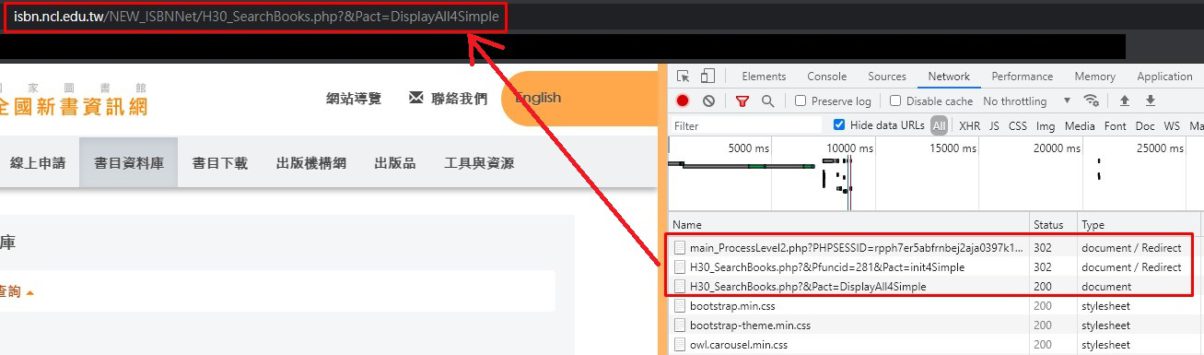
用POST方式帶入參數:headers、payload
payload就是搜尋字串
FO_SearchField0': 'ISBN','FO_SearchValue0': isbn,'FB_clicked': 'FB_開始查詢','FB_pageSID': 'Simple','FO_Match': '2','FO_每頁筆數': '10','FO_目前頁數': '1','FB_ListOri':''其中的FO_SearchField0′: ‘ISBN’,是搜尋欄位,這邊就是ISBN
‘FO_SearchValue0’: isbn, isbn是自設儲存ISBN字串的變數
這樣就能夠傳回搜尋結果
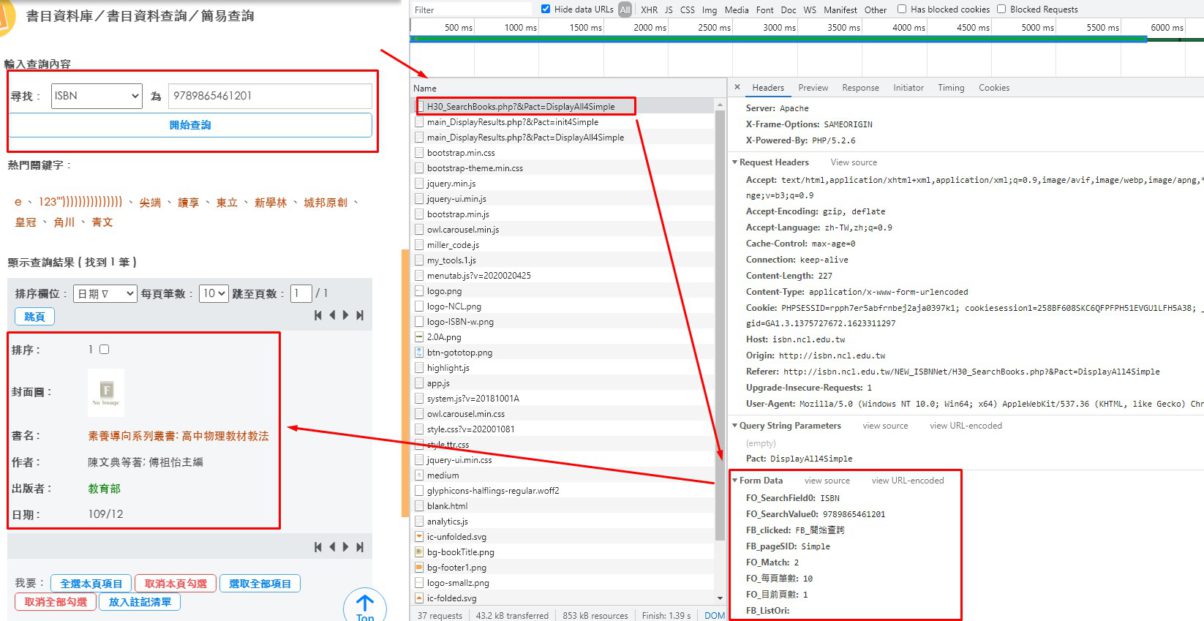
如果順利取得資料的話,資料會在類別名稱為.table-searchbooks的表格之中
接下來就是分別中tr td取出需要的資料內容
